TLDR: Delete any items without templates from your site’s content tree.
Recently when working with Sitecore Pages and my local docker-ized XM Cloud development environment, I ran into an error using the Pages editor. It had been working the previous week so I was stumped. My only clue was this error in the console: ApolloError: Object or reference not sent to instance of an object.
After scouring the documentation and re-doing my local setup, I was at a loss. Turns out, the solution was simple but (as of yet) undocumented, and probably the result of a recent update to Pages. Scouring the CM logs led me to the issue: items with no template.
Before signing off for the weekend, I had built a new component for this project. I pushed in all the code and serialization changes to my branch and opened a pull request for the team to review. When I came back to work on Monday, I swapped back to the development branch before spinning up my containers again.
Swapping branches and re-running serialization removed all the templates and renderings for my new component. However, it did not remove the test items I had created when developing the component, specifically the datasource items in the content tree. These items now had no template. Clicking them in content editor caused an error. And, it turns out, it was also causing the ApolloError in Pages.
To remove them, I had to use the Sitecore dbbrowser tool, at /sitecore/admin/dbbrowser.aspx. Once I did this, Pages was able to connect to my local environment again without issue.
Things move fast in the world of SaaS products like XM Cloud and Pages. This issue may be fixed next week, or it may hang around for a while. Regardless, it’s best to clean up any content items without a template in your local environments if you swap branches as you work on your project.
In the last post we went over setting up Experience Edge to set up a webhook whenever a publish is completed. In this post, we’ll handle receiving that webhook event to push published updates to our search index.
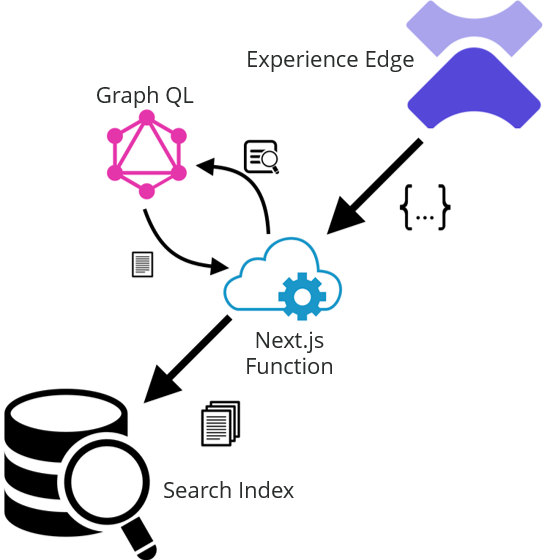
First let’s review the high-level architecture. Our webhook fires after a publish to Experience Edge completes. We need to send this to a serverless function in our Next.js app. That function will be responsible for parsing the json payload from the webhook and pushing any changes to our search index. This diagram illustrates the process:
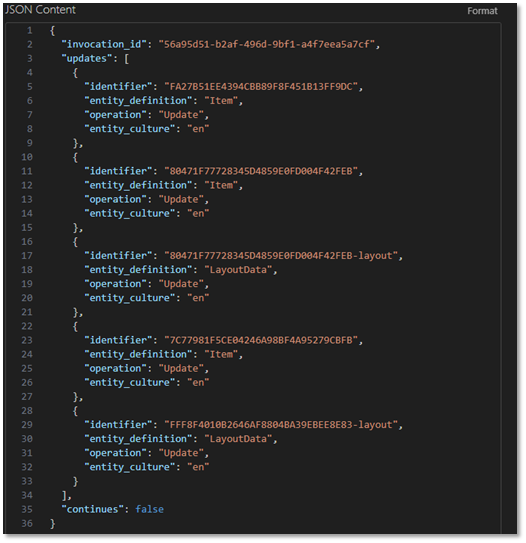
Before we build our serverless function, let’s take a look at the json that gets sent with the webhook :
Note that this webhook contains data about everything in the publish operation. For search index purposes, we’re interested in updates to pages on the website. This is represented by in the payload by "entity_definition": "LayoutData". Unfortunately, all we get is the ID of the item that was updated rather than the specific things that changed. That means we’ll need to query for the page data before pushing it to the search index.
Now that we understand the webhook data we’re dealing with, we need to make our function to handle it. If you’re using Vercel to host your web app, creating a serverless function is easy. Create a typescript file in the /pages/api folder in your app. We’ll call this handler “onPublishEnd.ts”. The function needs to do the following:
Loop over all “LayoutData” entries
Query GraphQL for that item’s field data
Validate the item is part of the site we’re indexing
Push the aggregate content data to the search provider
Let’s look at a sample implementation that will accomplish these tasks:
// Import the Next.js API route handler import { NextApiRequest, NextApiResponse } from 'next'; import { graphqlRequest, GraphQLRequest } from '@/util/GraphQLQuery'; import { GetDate } from '@/util/GetDate';
// Define the API route handler export default async function onPublishEnd(req: NextApiRequest, res: NextApiResponse) { // Check if the api_key query parameter matches the WEBHOOK_API_KEY environment variable if (req.query.api_key !== process.env.WEBHOOK_API_KEY) { return res.status(401).json({ message: 'Unauthorized' }); }
// If the request method is not POST, return an error if (req.method !== 'POST') { return res.status(405).json({ message: 'Method not allowed' }); }
let data; try { // Try to parse the JSON data from the request body //console.log('Req body:\n' + JSON.stringify(req.body)); data = req.body; } catch (error) { console.log('Bad Request: ', error); return res.status(400).json({ message: 'Bad Request. Check incoming data.' }); }
const items = [];
// Loop over all the entries in updates for (const update of data.updates) { // Check if the entity_definition is LayoutData if (update.entity_definition === 'LayoutData') { // Extract the GUID portion of the identifier const guid = update.identifier.split('-')[0]
// Invoke the GraphQL query with the request //console.log(`Getting GQL Data for item ${guid}`); const result = await graphqlRequest(request); //console.log('Item Data:\n' + JSON.stringify(result));
// Make sure we got some data from GQL in the result if (!result || !result.item) { console.log(`No data returned from GraphQL for item ${guid}`); continue; }
// Check if it's in the right site by comparing the item.path if (!result.item.path.startsWith('/sitecore/content/Search Demo/Search Demo/')) { console.log(`Item ${guid} is not in the right site`); continue; }
// Add the item to the items array items.push(result.item)
} catch (error) { // If an error occurs while invoking the GraphQL query, return a 500 error return res.status(500).json({ message: 'Internal Server Error: GraphQL query failed' }) } } } // Send the json data to the Yext Push API endpoint const pushApiEndpoint = `${process.env.YEXT_PUSH_API_ENDPOINT}?v=${GetDate()}&api_key=${process.env.YEXT_PUSH_API_KEY}`; console.log(`Pushing to ${pushApiEndpoint}\nData:\n${JSON.stringify(items)}`);
// Send all the items to the Yext Push API endpoint const yextResponse = await fetch(pushApiEndpoint, { method: 'POST', headers: { 'Content-Type': 'application/json', }, body: JSON.stringify(items), });
if (!yextResponse.ok) { console.log(`Failed to push data to Yext: ${yextResponse.status} ${yextResponse.statusText}`); }
This function uses the Next.js API helpers to create a quick and easy API endpoint. After some validation (including an API key we define to ensure this endpoint isn’t used in unintended manners), the code goes through the json payload from the webhook and an executes the tasks described above. In this case, we’re pushing to Yext as our search provider, and we’re sending all the item’s field data. Sending everything is preferable here because it simplifies the query on the app side and allows us to handle mappings and transformations in our search provider, making future changes easier to manage without deploying new code.
As the previous post stated, CREATE and DELETE are separate operations that will need to be handled with separate webhooks. There may still be other considerations you’ll need to handle as well, such as a very large publish and the need to batch the querying of item data and the pushes to the search provider. Still, this example is a useful POC that you can adapt to your project’s search provider and specific requirements.
In a previous post, we went over how to use GraphQL and a custom Next.js web service to crawl and index our Sitecore XM Cloud content into a search provider. That crawler runs on a schedule, so what happens when your authors update their content? They’ll need to wait for the next run of the crawler to see their content in the search index. This is a step back in capabilities from legacy Sitecore XP, which updated indexes at the end of every publish.
It’s possible to recreate this functionality using Experience Edge webhooks. Experience Edge offers quite a few webhook options (see the list here). To enable near real-time updates of our search index, we’ll use the ContentUpdated webhook, which fires after a publish to Edge from XM Cloud finishes. Let’s take a look at an example payload from that webhook:
As you can see, we have item data here and layout data. The layout data is what we’re interested in, as this represents our actual web pages, and that is what we want to index.
The general process is as follows:
Set up a receiver for this webhook. We’ll do this with a Next.js function.
Loop over the webhook payload and for each piece of LayoutData, then make a GraphQL query to get the field data from Experience Edge.
Finally, roll up the field data into a JSON object and push it to our search index.
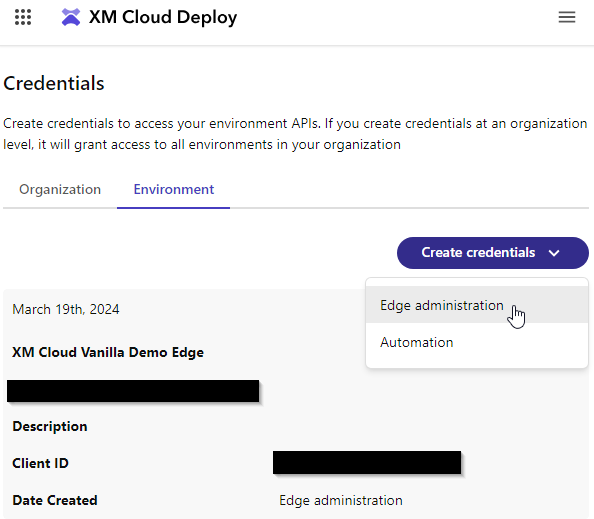
Let’s start by setting up our webhook. You’ll need to create an Edge administration credential in the XM Cloud Deploy app. Make note of the Client ID and Client Secret. The secret will only be displayed once, so if you lose it you will need to create new credentials.
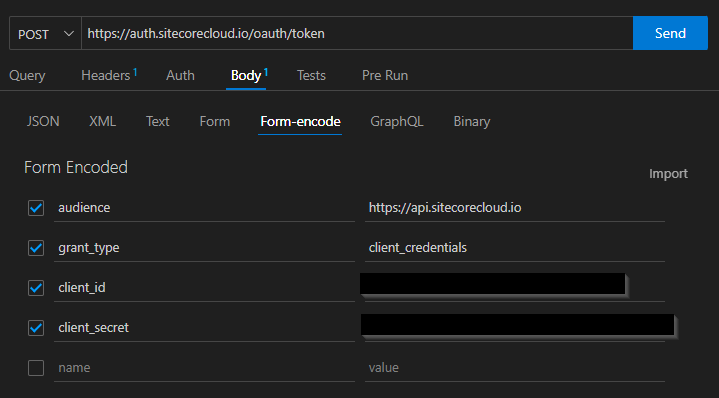
The next step is to create an auth token, you’ll need this to perform any Experience Edge administration actions. I used the ThunderClient plugin for Visual Studio Code to interact with the Sitecore APIs. To create an auth token, make a post request to https://auth.sitecorecloud.io/oauth/token with the following form data, using the client id and secret you just created in XM Cloud:
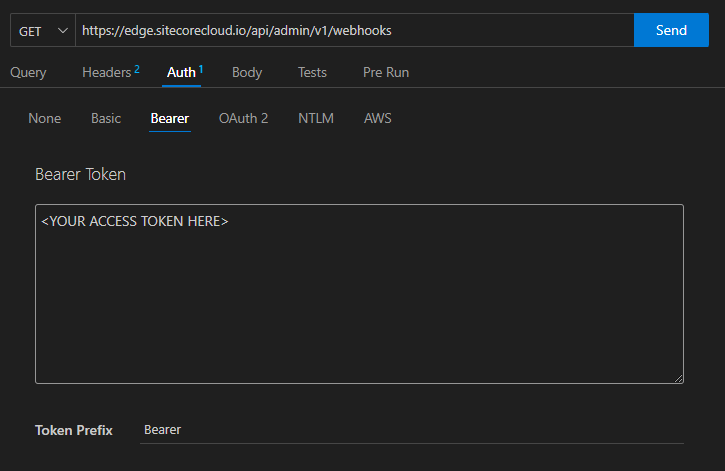
You’ll get back a json object containing an access token. This token is needed to be sent along with any API requests to Experience Edge. This token is passed as a Bearer Token in the Auth header. We can test it with a simple GET request that will list all the webhooks in this Edge tenant.
You should get back a json object containing a list of all the webhooks currently set up in your tenant (which is likely none to begin). The auth tokens expire after a day or so. If you get a message like edge.cdn.4:JWT Verification failed in your response, you have a problem with your token and should generate a new one.
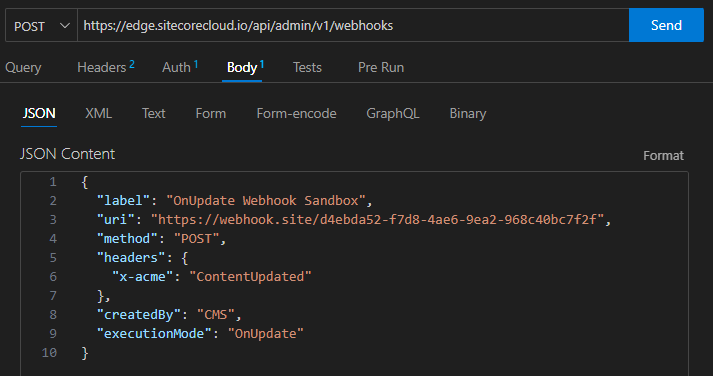
Next let’s create our ContentUpdated webhook. You’ll need something to receive the webhook. Since we haven’t created our function in Next.js yet, we can use a testing service like Webhook.site. Create a POST request to https://edge.sitecorecloud.io/api/admin/v1/webhooks with the following body:
The important parameters here are uri and executionMode. The uri is where the webhook will be sent, in this case our testing endpoint at webhook.site. The execution mode OnUpdate indicates this will fire when content is Updated. (Note: There are separate webhooks for create and delete, which you will probably need to set up later following this same pattern.)
Send this request and you’ll get a response that looks like this:
Try your GET request again on https://edge.sitecorecloud.io/api/admin/v1/webhooks, and you should see your webhook returned in the json response.
Try making some content updates and publishing from XM Cloud. Over at webhook.site, wait a few minutes and make sure you’re getting the json payload sent over. If so, you’ve set this up correctly.
To delete this webhook, you can send a DELETE request to https://edge.sitecorecloud.io/api/admin/v1/webhooks/<your-webhook-id>. Make sure you include your auth bearer token!
In the next post, we’ll go over handling this webhook to push content updates into our search index.
This is the first post in a series where I’ll go over a basic set up to configure Sitecore Search to crawl and query your XM Cloud content. This post will cover crawling and indexing your content using a Web Crawler and a Sitemap trigger.
To begin, it’s helpful to define some terms used in Sitecore Search. We’ll start with some structural terms.
Entity: This is a document in the search index. Sitecore Search ships with two types of entities, Product and Content. We will be using the Content entity.
Attribute: These are the fields on your entities. Attributes are defined on the entity and make up the schema of your content in the search index, much in the same way you’d use fields on a Sitecore template to define your content schema in the CMS.
Source: Sources are what you use to index content.
Connector: Sources have connectors, which control how the source receives data and how you read it to index content. A connector must be selected when creating a source. Each type of connector serves a different purpose and dictates what options are available to extract your content.
Trigger: Triggers are added to a source to control how the source data is fetched. Each type of trigger behaves differently.
Extractor: You use extractors to pull data from your source and write it to your entity’s attributes. The types of extractors available depend on the connector you’re using.
Before we begin, a few callouts. These apply to the state of the product as of the time of this blog post, so it’s possible future enhancements will mitigate these.
You must have the Tech Admin role in Sitecore search. This is a role above the Admin role, and you will probably need to have your organization’s primary contact request it for you from Support as it’s not available to be assigned to users via the UI.
When you make a change in Sitecore Search, you must Publish it for it to take effect. It is possible to revert a publish, but only to the previous version and no further. Your version history can be viewed via the UI, but it offers very little detail on what you changed.
Make only 1 change at a time, and publish between each change. If you change more than one thing, such as defining 2 or more attributes on an entity, then attempt to save and publish, the tool will error and lose your entity altogether, effectively disabling your instance. You can Revert your changes to the previously published state to resolve the error, but you will lose all your changes.
To start, select Administration from the left menu and then Domain Settings. If you don’t see this option, you need the Tech Admin role. Select Entities, and the popup will show your Content entity. Note the Attributes template. By default it is set to “Attributes Template for Content” and has several defined attributes already. You probably don’t need these, so change it to “Base Attributes Template”. Do this now before making any other changes, because once you start editing the entity you cannot change the template. Save and publish this.
Let’s define our attributes. With the base template, we get three to start: Id, Source, and Document Activeness. Of the three, Id is required. Let’s add some basic information like Title and Url.
Click Attributes in the subnav, then Add Attribute. You’ll be presented with a form. Let’s start by adding a Title field. Fill out the form as follows:
Entity: content
Display Name: Title
Attribute name: title (Note: use all lower case and no spaces for attribute names)
Placement: Standard
Data Type: String
Mark as: Check “Required” and “Return in api response”
Save and publish this. Repeat to create the Url attribute.
We’re making these fields required because we want all documents in the index to have a name and a url. These are the basic pieces of data we need for every document in our index. If a document is crawled and it is missing or otherwise cannot map required field data, the document is not indexed.
We also check “Return in api response” to make the contents of this field available in the search API. We will be checking this for any attribute we want included in the documents returned by the search API.
Next let’s add a taxonomy field called Topics. In Sitecore XMC, the Topic field is a multilist that allows authors to choose multiple Topic items to tag the content with. Add another attribute and define it like this:
Entity: content
Display Name: Topic
Attribute name: topic
Placement: Standard
Data Type: Array of Strings
Mark as: Check “Return in api response”
We’re not making Topic required because not all of our documents will have a topic. We’re choosing Array of Strings as the data type because the Topic may have multiple values. Save and publish again.
In order to facet on Topic, we need to perform another step. Select Feature Configuration from the subnav. You’ll see a lot of options here. If you select API Response, you’ll see all the attributes you added so far (assuming you checked “Return in api response”). Select Facets, then click Add Attribute. Add the Topic attribute here, save, and publish.
Now we have defined a barebones entity with fields for Id, Title, and Url, and included a single facet field on it called Topic. The next step is to set up our Source to crawl our Sitecore XM Cloud content. We’ll be using a Web Crawler connector with a Sitemap trigger to accomplish this.
Before your crawl, you need to make the data available to crawl. First, a sitemap. If you’re using SXA, you can configure a Sitemap to be generated automatically. On your pages, you’ll want to make the data available via meta tags. If you’ve set up open graph meta tags, you’ll have Title and Url covered. You’ll need to add another meta tag for Topics in your head web app like so, <meta name="topic" content="Topic A">
First we need to create the source. Select Sources from the left menu, then Add Source. In the dialog, name your source Sitemap Crawler and choose “Web Crawler” from the connector dropdown. (We’ll cover Advanced Web Crawler in another post). Save this and open the Source Settings screen.
Scroll down to Web Crawler Settings and click Edit. Set the Trigger Type to Sitemap. Set the URL to the url of your sitemap. You can use the Experience Edge media url to the SXA generated sitemap file if you haven’t configured middleware to handle /sitemap.xml in your head app (which you should!) Set Max Depth to 0, because we don’t want to drill into any links on the page; we’re relying on the Sitemap to surface all our content we need crawled. Save and publish.
Next we’re going to configure our Attribute extractors. On Attribute Extraction, click Edit. On the next screen, click Add Attribute. You can select the attributes to be mapped in the popup. Configure your attribute Extraction Types as Meta Tag. Set the Value to the name of the meta tag on your page, “og:title” for Title, “og:url” for Url, and “topic” for Topic. Again, I recommend doing one at a time and saving and publishing between mapping each extractor in order to avoid errors. If prompted to run the crawler while saving, do not do it yet.
In this Attribute Extractors screen you can click Validate in the top nav. That presents a dialogue that lets you put in a url and text the extractors, which is a great feature. Try pasting in some of your web pages and make sure you’re extracting all the data correctly.
Finally you can return to the Sources screen and click the Recrawl and Reindex button on the right hand side of the listed source you just created. This button looks like a refresh icon of 2 curved arrows in a circle.
It takes Sitecore Search a bit to fire up a crawl job, but you can monitor this from the Analytics screen under Sources. If all went well you should see all your documents from your sitemap in the content entity index. If not, you’ll see that an error occurred here and you can troubleshoot from there.
From here, feel free to add more attributes to fill out your content entity schema, and to put your crawler on a schedule from the Sources -> Crawler Schedule screen.
In the next post, we’ll cover using the API to query content from the index.
TLDR: Don’t put spaces in your field names for Sitecore headless builds.
Quick post about a bug I uncovered today working on an XM Cloud project with a .NET rendering host.
We’re seeing inconsistent behavior when mapping layout service field data to types in .NET. In short, fields with spaces in the name sometimes do not deserialize into .NET types when you attempt to do so with the SDK.
Consider a page with 2 fields: Topic and Content Type. In our code, we have a class that looks like this:
namespace MySite.Models.Foundation.Base
{
public class PageBase
{
[SitecoreComponentField(Name = "Content Type")]
public ItemLinkField<Enumeration>? ContentType { get; set; }
[SitecoreComponentField(Name = "Topic")]
public ContentListField<Enumeration>? Topic { get; set; }
}
}
When I create a component as a ModelBoundView, .AddModelBoundView<PageBase>("PageHeader") the fields map properly, and I get data in ContentType and Topic properties of my model.
When I try to map it from a service, like so:
namespace MySite.Services.SEO
{
public class MetadataService
{
private SitecoreLayoutResponse? _response;
public PageMetadata GetPageMetadata(SitecoreLayoutResponse? response)
{
_response = response;
PageBase pageBase= new PageBase ();
var sitecoreData = _response.Content.Sitecore;
sitecoreData.Route?.TryReadFields<PageBase>(out pageBase);
return pageMetadata;
}
}
}
I get no data in the Content Type field but I do in the Topic field. If I rename Content Type to ContentType, the field data is bound to the ContentType property as expected.
I dug into the code a little bit and it seems that the HandleReadFields method on the Sitecore.LayoutService.Client.Response.Model.FieldsReader is ignoring the property attributes: [SitecoreComponentField(Name = "Content Type")] Instead it is just using the property name, which of course has no spaces in it because it’s a C# identifier.
Until this bug is corrected, the workaround is to rename your fields to not have spaces in them.
Search is one of the biggest pieces of the puzzle when building a composable solution with Sitecore’s XM Cloud. Sitecore offers their own product, Sitecore Search, and there are a couple other search vendors that have native connectors. But what if you need to set up a search product that does not have a native connector to Sitecore, such as Yext? In this post, we’ll discuss how to use GraphQL + Experience Edge to crawl Sitecore via Yext’s API connector.
The first thing we want to do is figure out how we’ll get out content out of Sitecore. Ideally we want to be able to do this with a single query, rather than chaining queries together, in order to simplify the process of setting up the API crawler in Yext. For this, we’ll use a GraphQL search query. Let’s take a look at an example query:
Let’s take a look at this query, starting with the search filters.
_path allows us to query for every item that contains the rootPath in its path. For our site crawler, we’ll want to pass in the GUID of the site’s home page here.
_hasLayoutis a system field. This filter will exclude items that do not have a presenation assigned to them, such as folders and component datasources. We’ll want to pass in “true” here.
noIndex is a custom field we have defined on our page templates. If this box is checked, we want to exclude it from the crawl. We’ll pass in “1” here.
numResults controls how many results we’ll get back from the query. We’ll use 10 to start, but you can increase this if you want your crawl to go faster. (Be wary of the query response size limits!)
after is our page cursor. In our response, we’ll get back a string that points to the next page of results.
In the results area, we’re asking for some system fields like ID, name, path, and url. These are essential for identifying the content in Yext. After that, we’re asking for every field on the item. You may want to tune this to query just the fields you need to index, but for now we’ll grab everything for simplicity’s sake.
A question you may be asking is, “Why so many parameters?” The answer is to work around a limitation with GraphQL for Experience Edge:
Due to a known issue in the Experience Edge GraphQL schema, you must not mix literal and variable notation in your query input. If you use any variables in your GraphQL query, you must replace all literals with variables.
The only parameter we want to pass here is “after”, which is the page cursor. We’ll need our crawler to be able to page through the results. Unfortunately, that means we have to pass every literal value we need as a parameter.
In the results block we have our pages, along with all the fields we defined on the page template in the fields block. In the pageInfo block, we have endCursor, which is the string we’ll use to page the results in our crawler.
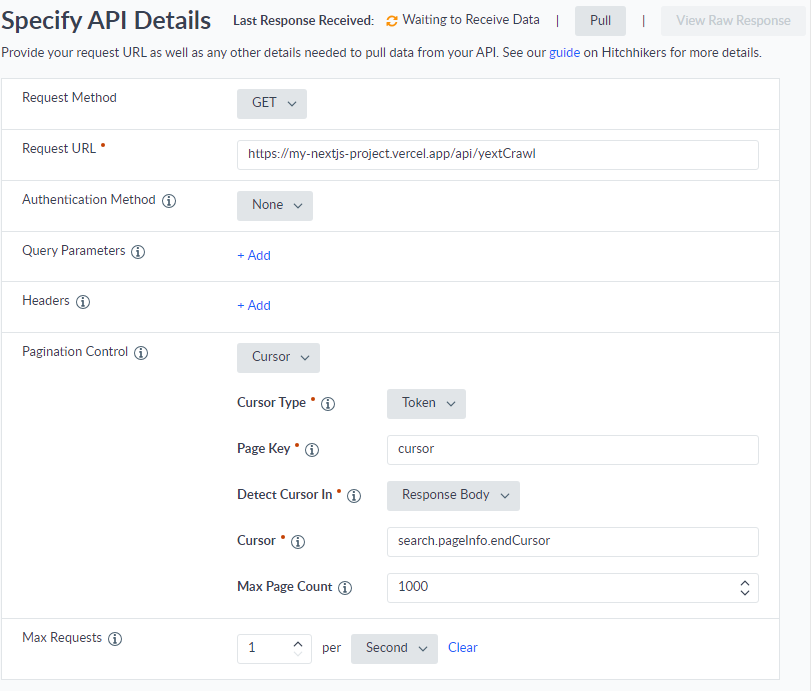
The next step is to set up the crawler in Yext. From Yext, you’ll want to add a “Pull from API” connector. On API Settings page, we can configure the crawler to hit Experience Edge in the Request URL field, pass our API key in the Authentication section, then put our GraphQL request in the Request Body section. Finally, we can set up the Pagination Control with our cursor. Easy, right?
Unfortunately, we’ll hit a problem here. Yext (as of this writing) only supports passing pagination parameters as query parameters. When we’re using GraphQL, we need to pass variables as part of the request body in the variables block. To work around this limitation, we’ll need to wrap our query in a simple API.
Next.js makes creating an API easy. You drop your api into the /pages/api folder and that’s it! Let’s make a simple API wrapper to take our page cursor as a query parameter and then invoke this query on Experience Edge. We’ll call our api file yextCrawl.ts.
We’re making a simple handler taking in a NextRequest and a NextResponse. We’ll check the request for our cursor parameter, if it exists. The GraphQL query we have as a literal string, cut and pasted from the XM Cloud playground where we tested it. The API key gets passed in the header, and we’ve configured this in our env.local and as an environment variable in Vercel.
Our request body will contain the query and the variables. This is where we’ll get around the limitation in the Yext Pull from API crawler. We’ll set up the cursor we pulled from the query parameters here. Our other variables we pass to the query are hard coded for the sake of this example.
Finally we use fetch to query Experience Edge and return the response. The result should be the same JSON we got from testing our query in the playground earlier. Once we deploy this api to Vercel, we can see it working at: https://my-nextjs-project.vercel.app/api/yextCrawl
Try hitting that url and see if you get back your Sitecore content. Then grab the endCursor value and hit it again, passing that value as the cursor parameter in the query string. You should see the next page of results.
Back in Yext, we’ll set up our Pull from API connector again, this time hitting our Vercel hosted API wrapper.
As you can see this is a lot easier to configure! Note the values of our cursor parameter under Pagination Control. These correspond to the cursor query parameter we defined in our wrapper API, and the endCursor data in the json response from our GraphQL query. It’s also important to configure the Max Requests setting. We’re limiting this crawler to 1 request per second so we don’t hit the request limit in Experience Edge.
You can test the connector with the Pull button on the top right. If you’ve set up everything correctly, you should see the View Raw Results button light up and be able to see your results in a modal window.
From here, you can configure the mappings of your Sitecore fields to your Yext entities. That is out of the scope of this post, but Yext’s documentation will help you there. One suggestion I will make is to map the Yext entity’s ID to the page’s Sitecore GUID, defined as id in our crawler query response.
Once it’s all set, save your connector, then you can run your crawler from the connector’s page by clicking “Run Connector”. If you’ve set everything up correctly, you should see your Sitecore content flowing into your Yext tenant.
Every once in a while, there comes a time when your automation fails, or it doesn’t do exactly what you need it to do, and you’re faced with a choice. Do you alter the automation scripts or do you just do it by hand? Recently I faced a situation when installing Sitecore 9.1 where SIF just didn’t create the collection databases. Rather than spend time debugging SIF, I decided to just create the collection databases by hand. Turns out, it wasn’t that hard.
My first instinct was to pull the .dacpac files from the Sitecore provided WDPs (web deploy packages) and deploy them to SQL myself. Job’s done right? But how do we create that ShardMapManagerDb database? There’s no package for that.
If you watch what SIF does during an installation, you may have noticed it runs something called the SqlShardingDeploymentTool.exe. Turns out, that tool does most of the work for us, and we just have to invoke it with the right parameters. Credit to this excellent post from Kelly Rusk that explains what these parameters do. Here are the steps to do it yourself.
Find the \App_Data\collectiondeployment folder in your XConnect instance. You can also extract this from the XConnect WDP package.
Create a collection_user in SQL. In my case SIF did this for me (despite not creating the collection DBs), but you will need to make one if doing this completely from scratch.
Prepare your command in notepad. You’ll need to pass the tool a lot of parameters, and feel free to reference the post linked earlier to understand them. Here’s one I used for reference:
Run a command prompt as administrator and navigate to the directory with the tool. Execute your prepared command. If all goes well you’ll see a tool.log in that folder that ends with *** Everything is done. Sitecore xDB Collection SQL Sharding Deployment Tool is about to end its work. *** Make sure you see your databases in SQL.
In the tool directory, you’ll see a few .sql scripts. We need to execute 2 of them to grant the proper permissions to the collection_user we created. In all cases, substitue the $(Username) variables with the name of your collection user.
CreateShardApplicationDatabaseUser.sql should be run against each of the shard databases. CreateShardManagerApplicationDatabaseUser.sql should be run against the shard map manager database. The other SQL scripts in this directory are unnecessary, they execute a subset of the commands in these two scripts.
If all went well you should be able to see XConnect connecting to and logging data to the newly created collection DBs. Happy Sitecoreing!
If you’ve been using Sitecore 9 or 9.1, you know that all the services the platform depends upon must communicate using trusted, secure connections. This includes Solr. Sitecore’s instructions and the scripts provided by SIF helpfully walk you through setting up a secure Solr installation as part of standing up your 9.1 environment. Jeremy Davis has also created a wonderful powershell script to install Solr with a self signed certificate that I’ve used quite a bit.
If you follow the steps outlined in these posts, you’ll have Solr Cloud up and running on separate machines. But, when it comes time to create a collection you’re going to run into a problem. You may see something like this in the response:
{"responseHeader":
{"status":0,"QTime":33294},
"failure":{"solr3:8983_solr":"org.apache.solr.client.solrj.SolrServerException:IOException occured when talking to server at: https://solr3:8983/solr","solr2:8983_solr":"org.apache.solr.client.solrj.SolrServerException:IOException occured when talking to server at: https://solr2:8983/solr"},
"success":
{"solr:8983_solr":
{"responseHeader":{"status":0,"QTime":2323},"core":"sample_collection_shard1_replica2"}}}
We created our certificates, the nodes are up and running, Zookeeper is aware of them all, but the Solr nodes can’t seem to communicate with each other. So what gives? If we dig into the logs on any of the Solr servers, we get a little more insight into the problem.
2019-03-05 19:04:49.869 ERROR (OverseerThreadFactory-8-thread-1-processing-n:solr2:8983_solr) [ ] o.a.s.c.OverseerCollectionMessageHandler Error from shard: https://solr3:8983/solr org.apache.solr.client.solrj.SolrServerException: IOException occured when talking to server at: https://solr3:8983/solr at org.apache.solr.client.solrj.impl.HttpSolrClient.executeMethod(HttpSolrClient.java:626) at ... Caused by: javax.net.ssl.SSLHandshakeException: sun.security.validator.ValidatorException: PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target at sun.security.ssl.Alerts.getSSLException(Alerts.java:192) ...
What we’re seeing here is the Solr servers don’t trust each other. We need to fix that.
There’s a couple of things we need to do here. First, we have to get the self-signed certificates we created for each Solr node and install them on the other servers. On each Solr server, do the following,
Open certlm.msc
Expand Trusted Root Certification Authority -> Certificates and find your Solr certificate you created.
Open the certificate and make a note of the thumbprint. We’ll need this later.
Export the certificate. Make sure you check Include Extended Properties and Mark this Certificate as Exportable in the dialogue.
When prompted for a password, use the same one you configured when installing Solr (the default is “secret”)
Once you have the certificates, you’ll need to install them on the other nodes. On each Solr server,
Import the certificates from the other 2 Solr nodes.
Try to hit the other Solr nodes from the browser on each server. For example, try accessing https://solr2:8983/solr/ from the Solr1 server. (You may need host file entries). If your certificates are installed properly, the browser will not warn you about an untrusted site.
There is one more thing we need to do. The Windows servers might trust our Solr nodes now, but the Solr applications themselves do not. If you take a look at the Solr installation steps, you’ll notice we’re creating a keystore file that holds the certificate for that Solr node (typically named . These keystore files needs to be updated to include the certificates from ALL of the Solr nodes, not just the one for the instance on that server.
We can easily do this with Powershell. We can do it with Java’s keytool.exe too, but we’re Sitecore people and probably more comfortable in Powershell! Remember those thumbprints we noted earlier? We’ll need them now.
Here’s the script, assuming your password is “secret”. Run this on any of the Solr nodes.
Take this generated solr-ssl.keystore.pfx file and copy it over the keystore file in each of the Solr nodes, then stop each node and restart them.
If we did everything correctly, when we try to create our collections again, it should go smoothly and you’ll be up and running with Solr Cloud and Sitecore 9.1.
For more information on the architecture of a Solr Cloud cluster and how to set one up for Sitecore, you can refer to my old blog series on the topic. It was written for 7.2, but the architecture principles haven’t changed. (including the need for a load balancer!)
Sitecore 9.1 comes bundled with a lot of new stuff, including a much improved Sitecore Install Framework. The process of setting up a local environment has been greatly streamlined, now you only need to run a script for installing prerequisites and then the XP0 installer itself. This gives you an instance of XConnect, Sitecore Identity server, both setup on HTTPS with trusted certificates. It will also install the Sitecore XP application for you and set it up on HTTP.
If you need to secure the Sitecore XP application as well, you could create a certificate in IIS and assign it to the HTTPS binding. However, this certificate won’t be trusted, and you’ll have the additional problem that Sitecore Identity Server won’t trust the site either, meaning you can’t log in over HTTPS. We’ll have to do a couple things to get past this.
You may see this error when trying to log into Sitecore 9.1 over HTTPS.
Create a new Trusted Certificate for IIS
First, we have to make a trusted certificate and assign it to our CM site. The certificate generated by IIS won’t cut it, because it uses the SHA1 encryption algorithm which is not accepted by modern browsers. Instead, let’s do what SIF does and make a certificate using Powershell. Alter the DnsName parameter to match the hostname of the Sitecore XP instance you’re working on.
Next we’ll need to export that certificate out of the Personal store and into the Trusted Root Certification Authority. Again, this is exactly what SIF does for XConnect and Identity Server. We can script this too, but it’s easy to do using the UI.
In Windows, run certlm.msc. This is the Local Computer Certificate manager.
Expand Personal -> Certificates and find the sc910.sc certificate.
Right click, and chose Tasks -> Export. Accept the defaults and save the certificate somewhere.
Expand Trusted Root Certification Authority, right click Certificates and choose All Tasks -> Import
Choose your certificate file you just created, and again accept the defaults.
If you did everything correctly, you should see this certificate available in IIS when you try to set up the HTTPS binding.
Setting up the HTTPS binding in IIS with our new certificate.
Try hitting your site in your browser, and you should not be prompted that the certificate is not trusted.
Chrome trusts our local Sitecore XP instance now.
However, we still can’t log into Sitecore. The login page says our client is unauthorized. What gives?
Configure Identity Server to Allow a New Client
We have to do one more thing, and that’s tell the Sitecore Identity Server about this new binding. To do this we need to edit a config in the identity server application. Open up \Config\production\Sitecore.IdentityServer.Host.xml in your identity server application folder. Look for the <Clients> block and add a line for our new secure XP binding.
Sitecore 9.1 has just hit, and with it comes a lot of exciting new features. You’ll probably be hearing and reading a lot about the Big Things they’re announcing with this release, such as the general availability of Sitecore Javascript Services (JSS), automated personalization with Cortex, Sitecore’s acquisition of digital asset manager StyleLabs, and their partnership with Salesforce.
However, there are some great quality of life enhancements coming with this release as well, which may be of particular interest to developers. Here’s a few that were highlighted.
Performance
Anyone who’s worked with Sitecore for a while, especially as a developer, has noticed how long it takes to start up the application. This can be a huge drag on productivity when you have to wait and wait for application pool recycles, especially if you’re in a rapid development cycle. You lose momentum, you lose focus, and it’s just annoying. The team at Sitecore has heard these complaints and made some serious strides on this in 9.1.
Sitecore showed some benchmarks and 9.1 is boasting a startup-time that’s cut in half. That’s time from a cold start of a CM instance to loading the Launchpad. Not bad! They’ve also cut the number of .dlls the /bin folder in half, increased the load time of the Content Editor by a factor of 6, and shaved some load time of the Experience Editor as well.
3rd Party Integrations
Sitecore has historically lagged behind in updating their integrations with supporting software. This was highlighted last year with the exposure of a security flaw in their Telerik version. In 9.1, we’ll see support for the latest versions of Sitecore’ supporting software, including Telerik, Newtonsoft Json.net, Solr, and of course .NET Core.
Horizon
The current Sitecore back-end has been essentially the same for many years, some CSS updates notwithstanding, and it’s lagging behind the competition. If you were at Symposium last year, it was mentioned during the closing keynote that Sitecore is working on an overhaul of their UI and authoring experience. This year they’ve announced the early-access availability of Horizon.
So, what is Horizon? Right now we’re not entirely sure. It’s meant to address the concerns of customers with the current Experience Editor. We know it’s an overhaul of the Experience Editor at least, but will it exist next to it, replace it outright, or complement it?
Sitecore is releasing an early access version of Horizon later this month and we’ll know a lot more. They want feedback, so as a developer you should download Horizon when it’s available, beat on it, and let them know what you think!
Native Indexing of Binary Content
Another small but welcome enhancement is the ability for the Content Search crawler to index PDF and MS Word files, out of the box. This was possible before with the installation of 3rd party tools, but Sitecore has heard their users and is wisely including this as a core feature.
That’s all for now. When Sitecore 9.1 hits, make sure to crack it open and put some of these changes through their paces. I certainly will be!




 Sitecore 9.1 has just hit, and with it comes a lot of exciting new features. You’ll probably be hearing and reading a lot about the Big Things they’re announcing with this release, such as the general availability of Sitecore Javascript Services (JSS), automated personalization with Cortex, Sitecore’s acquisition of digital asset manager StyleLabs, and their partnership with Salesforce.
Sitecore 9.1 has just hit, and with it comes a lot of exciting new features. You’ll probably be hearing and reading a lot about the Big Things they’re announcing with this release, such as the general availability of Sitecore Javascript Services (JSS), automated personalization with Cortex, Sitecore’s acquisition of digital asset manager StyleLabs, and their partnership with Salesforce.